Разрешение орграфа

Оглавление
По работе уже не первый раз сталкиваюсь с задачей разрешения графа, например, получить полный список зависимостей пакета или получить список групп пользователя, где группы могут включать друг друга. (Вообще граф зависимостей куда сложнее текущей темы, потому как дуги имеют маски версий, так что отложим этот вопрос на будущее.)
Итак, давайте сформулируем и ограничим задачу. У нас есть (в общем случае) ориентированный граф. Каждая вершина имеет уникальное имя и связанные с ней данные. Также отметим, что этот граф очень редко меняется в сравнении с запросом на разрешение зависимостей. На вход нам даются несколько имён вершин, мы должны вернуть список вершин, которые достижимы из заданных, или из которых можно достигнуть заданные (разрешить исходящий подграф или входящий).
Для решения задачи есть 2 алгоритма: поиск в глубину и поиск в ширину. Воспользуемся поиском в ширину. Для простоты описания рассмотрим разрешение исходящего графа. Суть алгоритма сводится к следующему:
- заведём очередь вершин графа;
- добавим в очередь заданные на старте вершины;
- пока очередь не пуста извлекаем вершину из очереди;
- для всех вершин достижимых из вершины, взятой из очереди: если вершина ещё не просмотрена, то отмечаем её как просмотренную и добавляем в очередь;
- вершину взятую из очереди помещаем в результат;
Всё достаточно просто, за исключением двух вопросов:
- как хранить очередь, ведь если у нас окажется полный граф, то в очереди окажутся все вершины графа?
- что значит пометим вершину как просмотренную и как потом узнать метку этой вершины?
На первый вопрос ответ содержится в шаге 5. Все вершины из очереди попадают в результат. Так если они всё равно попадут в результат, то почему бы результат и не использовать как очередь, просто завести указатель на начало очереди, а когда этот указатель догонит конец результата, это будет означать, что очередь пуста.
На второй вопрос ответ не столь прост. В постановке задачи мы упомянули, что каждая вершина имеет имя. И именно по именам происходит доступ к вершинам извне. То есть мы должны хранить вершины в хеш-таблице по их именам (или использовать деревья поиска, хотя в большинстве случаев время доступа важнее перерасхода памяти). И для хранения меток тоже хочется использовать хеш-таблицу. Но тут возникает другая проблема: одно дело хеш-таблица, которая построена один раз, а потом мы из неё читаем, совсем другое дело это строить огромную хеш-таблицу на каждый запрос. И дело даже не в расходе памяти, а в скорости её выделения/очистки. Давайте вернёмся к ограничениям: граф очень редко меняется в сравнении с запросом на разрешение зависимостей. Давайте на момент построения графа давать его вершинам числовые индексы. Тогда для хранения меток мы можем использовать булевый список длинной в количество вершин, ну, или пойти дальше и использовать битовые маски чтобы сократить количество используемой памяти ещё в 8 раз.
Вроде теперь непонятных мест не осталось, приступим к реализации:
package graph
import (
"fmt"
)
type direction int8
const (
// In is a incoming direction
In direction = iota
// Out is a outgoing direction
Out
)
type vertex struct {
id int
name interface{}
data interface{}
link [2][]*vertex
}
func (v *vertex) String() string {
return fmt.Sprintf("%d:%s", v.id, v.name)
}
func (v *vertex) addLink(dir direction, u *vertex) bool {
if len(v.link[dir]) == 0 {
v.link[dir] = append(v.link[dir], u)
return true
}
var l, r, c int
l = 0
r = len(v.link[dir]) - 1
for l < r {
c = l + (r-l)/2
if v.link[dir][c].id == u.id {
return false
}
if v.link[dir][c].id < u.id {
l = c + 1
} else {
r = c
}
}
if v.link[dir][r].id == u.id {
return false
}
if v.link[dir][r].id < u.id {
v.link[dir] = append(v.link[dir], u)
} else {
v.link[dir] = append(v.link[dir], nil)
copy(v.link[dir][r+1:], v.link[dir][r:])
v.link[dir][r] = u
}
return true
}
Структура vertex описывает вершину со связями до других вершин. Для хранения связей используется двойной список link. Также при добавлении связи мы должны проверить что связь не была представлена ранее, для этого используем бинарный поиск по установленным ранее связям. Метод String использовался для отладки, впрочем мешать не будет.
Также опишем битовый массив меток:
package graph
type labels []uint8
func newLabels(n int) labels {
l := make(labels, n/8+1)
for i := range l {
l[i] &= 0
}
return l
}
func (l labels) check(n int) bool {
return l[n/8]&(uint8(1)<<uint(n%8)) > 0
}
func (l labels) set(n int) {
l[n/8] |= uint8(1) << uint(n%8)
}
Ну, и собственно сам граф:
package graph
import (
"sync"
"github.com/pkg/errors"
)
// Graph is a main object of this package
type Graph struct {
sync.RWMutex
vertices map[interface{}]*vertex
labPool sync.Pool
verPool sync.Pool
}
// New Graph constructor
func New(V map[interface{}]interface{}, E [][2]interface{}) *Graph {
g := &Graph{
vertices: make(map[interface{}]*vertex, len(V)),
}
g.labPool = sync.Pool{
New: func() interface{} {
return newLabels(len(g.vertices))
},
}
g.verPool = sync.Pool{
New: func() interface{} {
return make([]*vertex, len(g.vertices))[:0]
},
}
i := 0
for name, data := range V {
g.vertices[name] = &vertex{
id: i,
name: name,
data: data,
}
i++
}
for _, e := range E {
if u, ok := g.vertices[e[0]]; ok {
if v, ok := g.vertices[e[1]]; ok {
g.addLink(u, v)
}
}
}
return g
}
// AddVertex to graph
func (g *Graph) AddVertex(name, data interface{}) bool {
g.Lock()
defer g.Unlock()
if _, ok := g.vertices[name]; ok {
return false
}
g.vertices[name] = &vertex{
id: len(g.vertices),
name: name,
data: data,
}
return true
}
// AddLink from src to dst
//
// Return error if one of vertex not found. Return true if link created
// and false if link already exists. Concurrent safe.
func (g *Graph) AddLink(src, dst interface{}) (bool, error) {
g.Lock()
defer g.Unlock()
if u, ok := g.vertices[src]; ok {
if v, ok := g.vertices[dst]; ok {
return g.addLink(u, v), nil
}
return false, errors.Errorf("vertex %q not found", src)
}
return false, errors.Errorf("vertex %q not found", src)
}
func (g *Graph) addLink(u, v *vertex) bool {
if len(u.link[Out]) < len(v.link[In]) {
if u.addLink(Out, v) {
return v.addLink(In, u)
}
return false
}
if v.addLink(In, u) {
return u.addLink(Out, v)
}
return false
}
// Resolve all achievable vertices from given srcs in given direction
func (g *Graph) Resolve(dir direction, srcs ...interface{}) []interface{} {
lab := g.labPool.Get().(labels)
res := g.verPool.Get().([]*vertex)
for _, src := range srcs {
if v, ok := g.vertices[src]; ok {
lab.set(v.id)
res = append(res, v)
}
}
for i := 0; i < len(res) && len(res) < len(g.vertices); i++ {
for _, v := range res[i].link[dir] {
if !lab.check(v.id) {
lab.set(v.id)
res = append(res, v)
}
}
}
g.labPool.Put(lab)
dd := make([]interface{}, len(res))
for i, v := range res {
dd[i] = v.data
}
g.verPool.Put(res)
return dd
}
Для оптимизации работы с памятью используем 2 sync.Pool‘а для результирующего списка/очереди и массива меток. И ещё одна оптимизация: если в результирущем списке содержатся все вершины графа, тогда можно заканчивать обход (строка 123). На сильно связанных графах это условие позволит сильно сэкономить операции.
Напоследок напишем тесты и бенчмарки:
package graph
import (
"fmt"
"math/rand"
"testing"
"time"
"github.com/stretchr/testify/require"
)
func TestGraph(t *testing.T) {
const n = 5
V := make(map[interface{}]interface{}, n)
for i := 0; i < n; i++ {
V[i] = i
}
E := [][2]interface{}{
{0, 1}, {0, 2},
{1, 2}, {1, 3},
{2, 3}, {2, 0},
{3, 2}, {3, 0},
{4, 0}, {4, 1},
}
g := New(V, E)
t.Run("New", func(t *testing.T) {
ok, err := g.AddLink(0, 1)
require.NoError(t, err)
require.False(t, ok)
ok, err = g.AddLink(0, 10)
require.Error(t, err)
require.False(t, ok)
ok, err = g.AddLink(3, 0)
require.NoError(t, err)
require.False(t, ok)
})
t.Run("AddVertex", func(t *testing.T) {
require.False(t, g.AddVertex(0, 0))
require.True(t, g.AddVertex(10, 10))
})
t.Run("AddLink", func(t *testing.T) {
ok, err := g.AddLink(0, 3)
require.NoError(t, err)
require.True(t, ok)
ok, err = g.AddLink(0, 10)
require.NoError(t, err)
require.True(t, ok)
ok, err = g.AddLink(0, 10)
require.NoError(t, err)
require.False(t, ok)
})
t.Run("Resolve", func(t *testing.T) {
res := g.Resolve(Out, 0)
require.Len(t, res, 5)
require.Contains(t, res, 0)
require.Contains(t, res, 1)
require.Contains(t, res, 2)
require.Contains(t, res, 3)
require.Contains(t, res, 10)
})
}
func BenchmarkResolve(b *testing.B) {
n := 500000
step := 100000
V := make(map[interface{}]interface{}, n)
for i := 0; i < n; i++ {
V[i] = i
}
g := New(V, nil)
for i := 0; i < n*(n-1); i += step {
timer := time.NewTimer(10 * time.Second)
for j := 0; j < step; {
select {
case <-timer.C:
b.Log("too long")
return
default:
}
src := rand.Intn(n)
dst := rand.Intn(n)
if ok, _ := g.AddLink(src, dst); ok {
j++
}
}
b.Run(fmt.Sprintf("%d", i), func(b *testing.B) {
b.ReportAllocs()
for j := 0; j < b.N; j++ {
g.Resolve(Out, 0)
}
})
}
}
Для бенчмарка будем строить случайный граф. Очевидно, что сложность алгоритма \(O(m)\), то есть прямо пропорциональна числу связей, так что зафиксируем число вершин на 500'000 и будем увеличивать число связей по 100'000 за шаг. Получим следующий график:
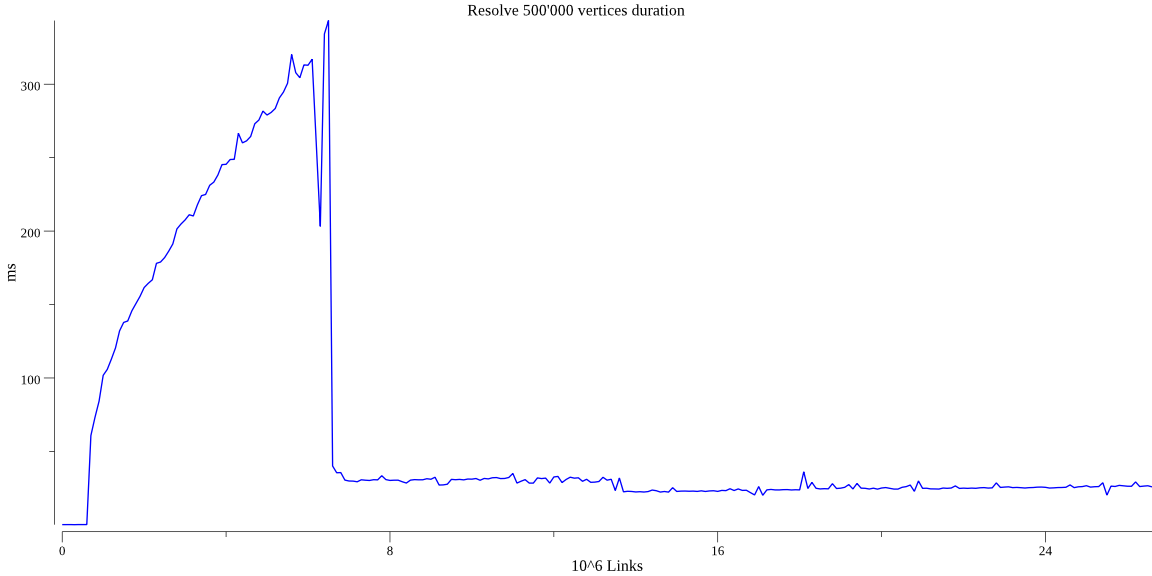
Время обработки запроса от количества связей
На графике видно место где сработала введёная нами оптимизация (строка 123). В районе 6'000'000 связей граф становится полностью достижим и время ответа резко сокращается.
Количество памяти зависит по большей части от размеров результирующего списка:
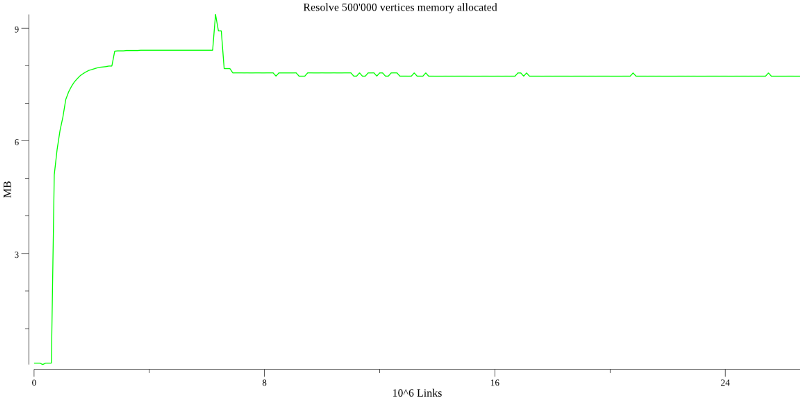
Расход памяти от количества связей
Также в районе 6'000'000 достигает своего максимума и стабилизируется на примерно 8MB.
Вообще для сильносвязных графов надо искать другие решения, возможно предварительно высчитывать компоненты связности и хранение списков недостижимых вершин.
Весь код доступен в репозитории https://github.com/vporoshok/graph-go